Image by Author
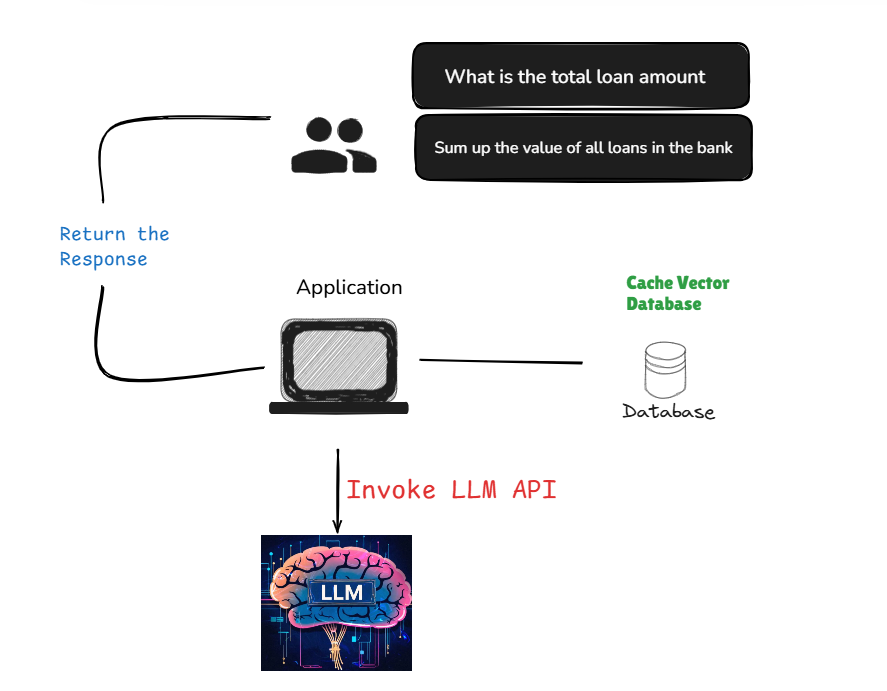
Text-to-SQL transformed how enterprises interact with their data. However, for similar questions, regenerating SQL from scratch isn't always the most efficient approach.
When LLMs start translating natural language into database queries, it marked a significant advancement in data democratization. Non-technical users could finally ask complex questions of their data without learning SQL.
Among the solutions in this space, Denodo AI SDK stands out by connecting and combining enterprise data silos through a logical data layer, providing secure, governed access to structured data through natural language.
With remarkable accuracy, Denodo's text-to-SQL functionality translates questions into Denodo's Virtual Query Language (VQL). While this process produces excellent results, it presents an optimization opportunity.
💡 Key Question
Why regenerate SQL from scratch when users ask similar questions with minor variations?
By implementing a semantic caching layer on top of Denodo AI SDK, we've seen dramatic performance improvements, making responses 9x faster while maintaining all of Denodo's powerful governance and security features. This enhancement makes Denodo's already robust platform even more responsive for users asking variations of common questions.
In this article, I'll show how semantic caching can turbocharge Denodo AI SDK, complete with code examples and performance metrics you can implement in your environment.
🌐 Works with Any Data Platform
Semantic caching is platform-agnostic! You can apply this approach to any data platform including:
- • Cloud Data Warehouses: Snowflake, Databricks, Redshift, BigQuery
- • RDBMS: Oracle, SQL Server, PostgreSQL, MySQL
- • NoSQL: MongoDB, Cassandra
- • Data Lakes: Delta Lake, Iceberg
Why Denodo for this demo? I'm using Denodo AI SDK because Denodo's data virtualization platform excels at building a unified semantic layer across all your data sources. It provides a logical abstraction layer that connects disparate data silos (databases, cloud warehouses, APIs, files) into a single governed view — making it ideal for enterprise Text-to-SQL applications. The semantic caching technique demonstrated here works seamlessly with Denodo while maintaining its governance, security, and data abstraction capabilities.
What is Semantic Caching?
Semantic caching stores the meaning behind queries, retrieving information based on intent rather than exact matches. This provides more relevant results than traditional caching while being faster than direct LLM responses.
Like a perceptive librarian who understands the context of requests rather than just matching titles, semantic caching intelligently retrieves data that best aligns with the user's actual needs.
Key Components
- Embedding model: Creates vector representations of data to measure query similarity.
- Vector database: Stores embeddings for fast retrieval based on semantic similarity rather than exact matches.
- Cache: Central storage for responses and their semantic meaning.
- Vector search: Quickly evaluates similarity between incoming queries and cached data to determine the best response.
Benefits Over Traditional Caching
Traditional caching speeds up access to frequently requested information but disregards query meaning. Semantic caching adds an intelligent layer that understands query intent, storing and retrieving only the most relevant data. By using AI embedding models to capture meaning, semantic caching delivers faster, more relevant results while reducing processing overhead and improving efficiency.
The Challenge: Denodo AI SDK and the Cost of Natural Language
Denodo's data virtualization platform excels at solving trusted data challenges by connecting and combining data silos through a logical data layer.
Denodo's AI feature — Denodo AI SDK offers functionality which helps AI Developers to build an LLM application which translates natural language questions into Denodo's Virtual Query Language (VQL) with remarkable accuracy that retrieves the Enterprise data, also it is remarkably easy to integrate structured data into text-to-SQL LLM applications with robust governance and security.
🚨 The Cost Challenge
However, this powerful capability comes with a cost challenge. Every time a user asks a question, the standard Denodo AI SDK workflow involves:
- 1. Vector search to find relevant tables and columns
- 2. Analysis of database schema and relationships
- 3. Understanding of filters and aggregations
- 4. Generation of valid VQL (Denodo SQL)
- 5. Execution of the query and formatting results
For organizations handling hundreds of queries daily through Denodo AI SDK, each consuming thousands of tokens in a large language model, this quickly becomes unsustainable from both a cost and performance perspective.
How could we preserve Denodo's excellent data governance while making the text-to-SQL conversion more efficient?
Spotting the Opportunity — Why Redo What's Already Done?
The key insight is that most database questions follow patterns with minor variations. When analysts ask "How many customers in California?" followed by "Count clients in New York," they're asking the same question with one parameter changed. We can enhance performance for these similar queries by implementing a semantic caching pattern:
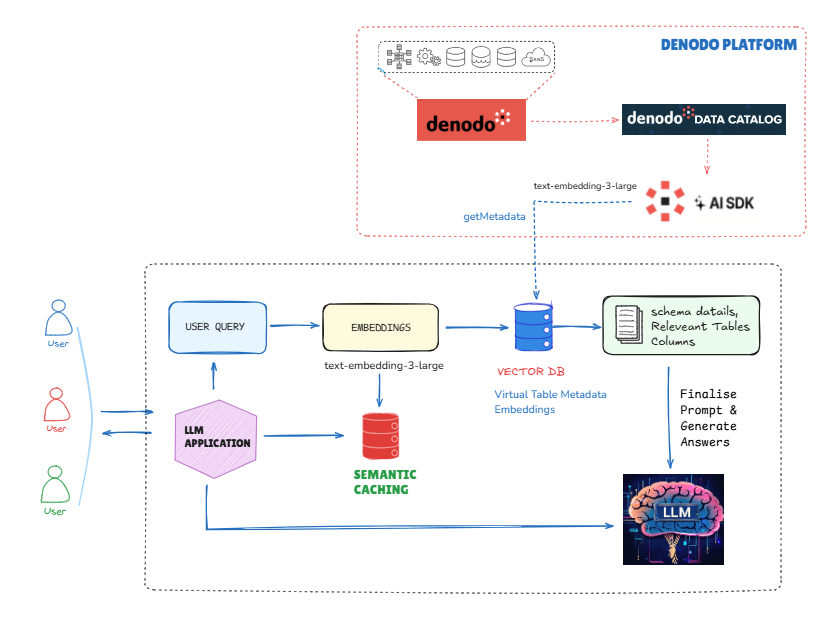
Image by Author
- Vector-based Cache Database — Store natural language questions, their SQL queries, and query explanations in a vector database that enables semantic search
- Match similar questions — When a new question arrives, use vector embeddings to find semantically similar previously asked questions
- Validate semantic relationship — Use a small language model or cheaper models to verify if the questions truly have the same intent but with different parameters
- Modify the existing SQL query — Instead of generating a completely new SQL, adapt the cached query by changing only the necessary parts
- Execute and validate — Run the modified query against the denodo's data catalog to retrieve real-time results with secured layer.
This approach preserves all the benefits of Denodo's trusted data platform while making it significantly more responsive and cost-effective for common query patterns.
Step 1: Designing the Solution — A Smart Two-Path Workflow
The trick is to blend Denodo's full power for new questions with a fast lane for similar ones. My solution uses a semantic cache with two paths:
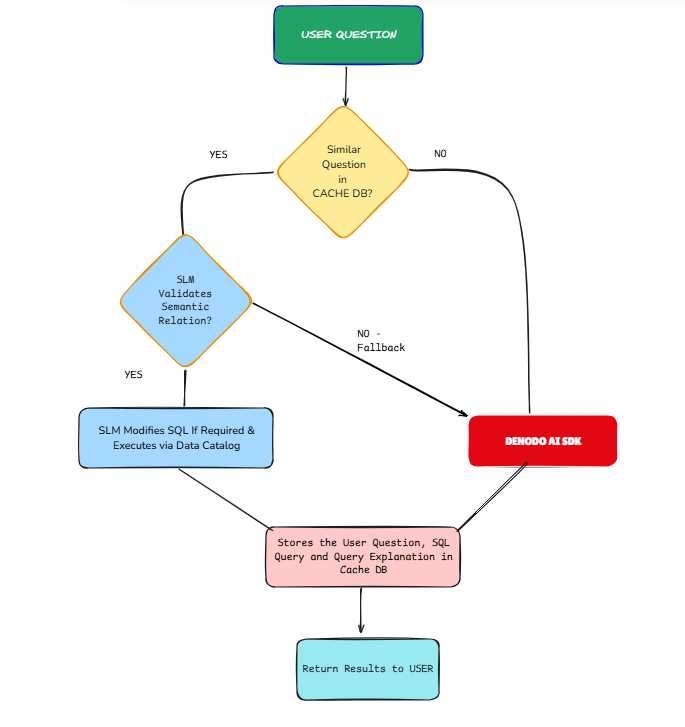
Image by Author
✅ Cache Check
When someone asks "Count the number of clients in NewYork," we check our cache/vector database (FAISS)
✅ Validation Layer
- • Vector similarity identifies candidate matches like "How many customers do we have in the state of CA?"
- • A small language model validates semantic relatedness
- • This prevents false positives while maintaining high accuracy
✅ Execution Paths
- • Cache Hit: For repeated/similar questions, modify the existing SQL (changing "CA" to "NY") if required and execute the SQL.
- • Cache Miss: For actual questions, use Denodo AI SDK's standard pipeline (fallback mechanism)
This complementary approach means we get the best of both worlds: Denodo's powerful data virtualization for novel questions and lightning-fast responses for similar ones.
Step 2: Building the Core — Semantic Cache in Python
Let's get hands-on. The system hinges on a SemanticCache class that pairs vector embeddings with a FAISS index for lightning-fast similarity checks. Here's how it starts:
class SemanticCache:
def __init__(self, embedding_model, similarity_threshold=0.90):
self.embedding_model = embedding_model
self.similarity_threshold = similarity_threshold
self.cache = {
"questions": [],
"embeddings": None,
"sql_queries": [],
"results": []
}
self.faiss_index = faiss.IndexFlatL2(3072) # 3072 dims for text-embedding-3-largeKey Components
- Embedding Model: I used OpenAI's text-embedding-3-large to convert questions into vectors.
- FAISS Index: Stores embeddings for fast lookups.
- Threshold: 0.90 ensures only truly similar questions match.
When a question comes in, find_similar_question checks the cache:
def find_similar_question(self, question):
if self.faiss_index.ntotal == 0:
return None, None, None, 0.0
query_vector = np.array([self.embedding_model.embed_query(question)], dtype=np.float32)
distances, indices = self.faiss_index.search(query_vector, 1)
similarity = 1 - (distances[0][0] / 20) # Normalize distance to similarity
if similarity >= self.similarity_threshold:
index = indices[0][0]
return (
self.cache["questions"][index],
self.cache["sql_queries"][index],
self.cache["results"][index],
similarity
)
return None, None, None, 0.0Step 3: Validating Similarity — The LLM Gatekeeper
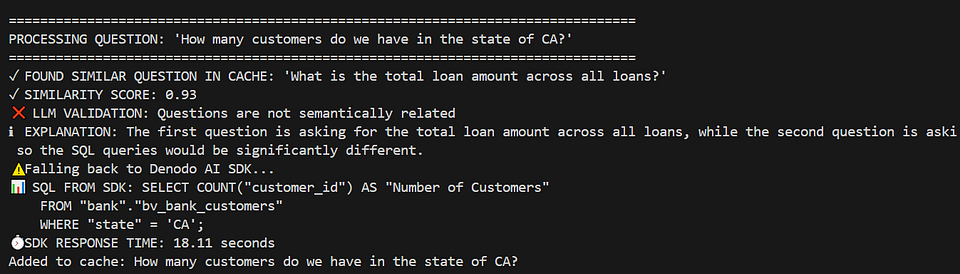
Vector similarity alone isn't foolproof. "List top 5 loans" and "List top 5 customers" might look close in vector space but need different SQL.
In the below example, the system initially found a high similarity score (0.93) between the question 'How many customers do we have in the state of CA?' and the cached question 'What is the total loan amount across all loans?'.
However, despite the high similarity score, the two questions are semantically different — the first asks for a count of customers in a specific state, while the second asks for a total loan amount. This mismatch occurred because the cache contained very limited data, causing the similarity algorithm to overestimate relevance. To mitigate this, I used an SLM for semantic validation, which correctly identified the questions as unrelated. As a result, the system fell back to the Denodo AI SDK to generate the correct SQL query, ensuring accurate results.
Code Snippet
def are_questions_semantically_related(question1, question2):
"""
Use a small, cost-effective language model to determine if two questions
are semantically related enough to potentially reuse and modify the SQL.
This function uses GPT-3.5 Turbo, but could easily be replaced with
open-source models like Llama 3 or Mistral for even greater cost savings.
"""
llm = ChatOpenAI(api_key=OPENAI_API_KEY, model="gpt-3.5-turbo")
prompt = ChatPromptTemplate.from_template("""
I need to determine if two questions about a banking database are semantically related enough
that the SQL query for one could be modified to answer the other.
Question 1: {question1}
Question 2: {question2}
First, analyze what each question is asking for:
- What entity/table is each question about?
- What operation is being performed?
- What filters or conditions are applied?
Then determine if they are related enough that one SQL could be modified to answer the other.
Output your decision as a JSON object with these fields:
{{
"are_related": true/false,
"explanation": "Brief explanation of your reasoning",
"primary_entity": "The main entity/table being queried",
"operation_type": "The type of operation",
"parameter_differences": "Description of any parameter differences"
}}
""")
response = llm.invoke(prompt.format(question1=question1, question2=question2))
# Extract JSON response and return decision
# ...
return resultStep 4: Modifying SQL — Precision Tweaks
Once validated, we tweak the cached SQL for the new question. Let's look at a real example from my testing:

Image by Author
In this example, when processing "Count the number of clients in NewYork":
- The system found a similar question "How many customers do we have in the state of CA?" with 0.93 similarity
- The LLM confirmed these are semantically related — both counting customers in specific states
- It modified only the state code in the WHERE clause from 'CA' to 'NY'
- The query executed successfully in just 1.42 seconds
- The result showed 5 clients in NewYork
⚡ Performance Win
This entire process took just 1.42 seconds, compared to the 10+ seconds it would have taken with the standard Denodo AI SDK approach. The modification was minimal and precise, changing just the state code while preserving the query structure.
Code Implementation
def modify_sql_query(original_query, new_question, original_question):
"""
Use a small language model (GPT-3.5 Turbo) to modify the original VQL query.
This function could be implemented with open-source models like Llama 3 or Mistral
for further cost reduction or on-premises deployment.
"""
llm = ChatOpenAI(api_key=OPENAI_API_KEY, model="gpt-3.5-turbo")
prompt = ChatPromptTemplate.from_template("""
Original question: {original_question}
Original VQL query: {original_query}
New question: {new_question}
Modify the VQL query to answer the new question. Only change what's necessary.
Preserve the overall structure and intent of the query.
Return ONLY the modified VQL query, nothing else.
""")
response = llm.invoke(prompt.format(
original_question=original_question,
original_query=original_query,
new_question=new_question
))
return response.content.strip()The Results: 9X Performance Improvement
The semantic caching layer dramatically improves performance for common query patterns while maintaining the full power and governance of Denodo AI SDK for novel questions.
Key Takeaways
💡 What You've Learned
- • Semantic caching can make Text-to-SQL systems up to 9x faster
- • Vector embeddings enable intelligent query matching beyond exact string comparison
- • LLM validation prevents false positives in similarity matching
- • SQL modification is more efficient than regenerating queries from scratch
- • This approach works alongside existing systems like Denodo AI SDK
Try It Yourself
Full source code and implementation examples available on GitHub
Quick Setup
- 1. Install dependencies:
pip install faiss-cpu langchain openai - 2. Set up your embedding model and FAISS index
- 3. Implement the SemanticCache class
- 4. Integrate with your Text-to-SQL system
Need Help Implementing Semantic Caching?
I offer consulting services for Text-to-SQL optimization, semantic caching implementation, and performance tuning. Let's discuss how to make your system faster and more cost-effective.
Schedule a Consultation