When you ask an AI to generate SQL from a natural language question, what you get back often looks impressive—until a database expert examines it. Hidden within that syntactically correct query might be missing joins that would return incorrect data, absent indexes that would cause performance issues, or complex subqueries where simpler approaches exist.
In production environments, these inefficiencies aren't just theoretical problems—they can bring critical systems to a halt or lead to business decisions based on flawed data.
Why are data analysts still the kings of writing database queries?
Domain expertise. Business context. Optimization instinct. While AI stumbles with complexity, human experts craft elegant, efficient solutions. They don't just write queries that work—they create queries that excel.

HVSR: Human-Verified SQL Repository Approach
Today's Data Dilemma
Organizations race to democratize data access with text-to-SQL AI tools. These tools make databases approachable for everyone. But they consistently miss the optimizations that human experts instinctively apply.
The challenge is clear: How do you make data accessible through AI without sacrificing the query quality your business depends on?
Traditional Solution: The Limitations of Fine-Tuning
The traditional approach to improving LLM-generated SQL is fine-tuning—training the model on domain-specific examples to improve its performance. While fine-tuning has its place, it comes with significant limitations:
✓ Pros of Fine-Tuning
- Improves general performance across similar questions
- Can incorporate domain-specific knowledge
- Works without human intervention at query time
✗ Cons of Fine-Tuning
- Requires large datasets of high-quality examples
- Expensive in terms of computing resources and expertise
- Results still lack the precision of human-optimized queries
- "Black box" improvement without clear explanations
- Struggles with edge cases and complex optimizations
Fine-tuning might produce better queries, but it rarely achieves the gold standard of human SQL expertise. More importantly, it fails to capture your organization's growing, evolving nature of SQL knowledge.
The Evolution of Text-to-SQL: From Bronze to Gold
If you're familiar with Medallion Architecture in data lakehouses, you'll recognize the concept of progressive data refinement through bronze, silver, and gold layers. The same paradigm can be applied to text-to-SQL systems:
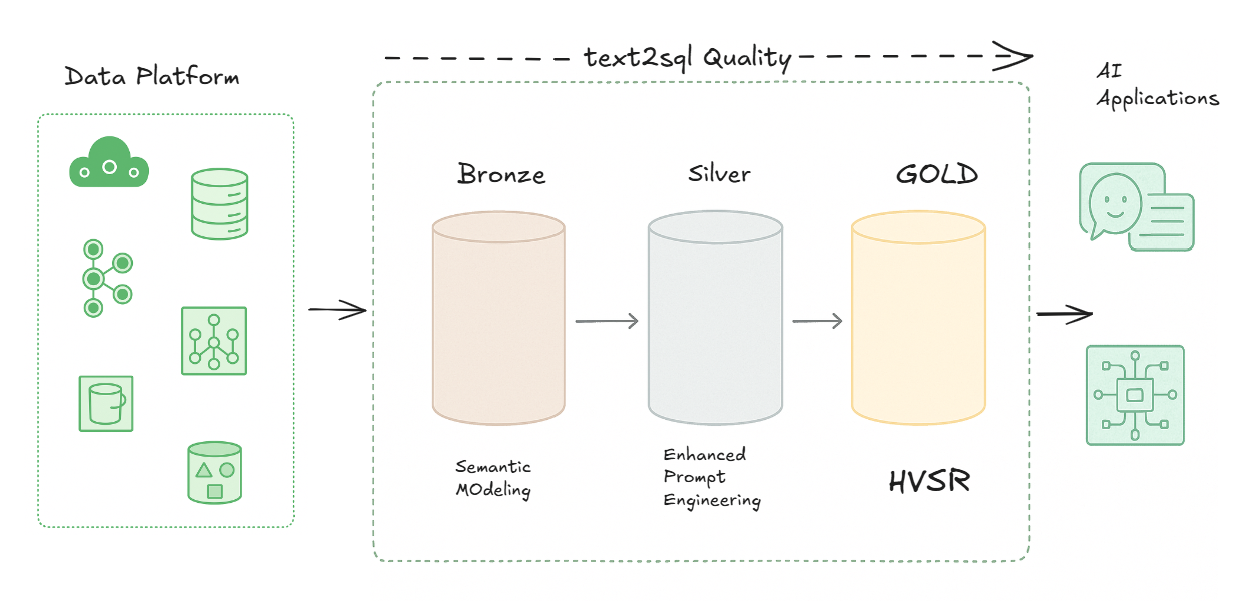
Bronze, Silver, Gold: Progressive Text-to-SQL Quality
🥉 Bronze Level: Semantic Modeling
- • LLMs provided with basic database schema details
- • Includes table names, column definitions, and relationships
- • Can generate syntactically correct SQL, but often with suboptimal approaches
- • Missing deeper knowledge about indexes, partitioning, or query optimization
- • Equivalent to raw, structured data in the bronze-silver-gold paradigm
🥈 Silver Level: Enhanced Prompt Engineering
- • Builds on bronze by adding sophisticated prompting techniques
- • Includes detailed instructions on SQL best practices
- • May incorporate examples of good query patterns
- • Still lacks the deep expertise of human SQL specialists
- • Similar to processed data that's validated but not fully optimized
🥇 Gold Level: Human-Verified SQL Repository (HVSR)
- • Curated collection of human-verified, optimized SQL queries
- • Each query represents expert knowledge applied to specific business questions
- • Includes rich metadata about optimization choices and business context
- • LLMs can match new questions to these gold-standard examples
- • True "analytics-ready" queries, parallel to gold data that's ready for business consumption
Most text-to-SQL systems today operate at the bronze or silver level. While they can produce working queries, they lack the deep optimization, contextual awareness, and proven reliability that come from human verification. HVSR creates a systematic approach to developing and maintaining gold-standard queries through human verification and intelligent reuse.
What is HVSR, and What Problem Does It Solve?
Human-Verified SQL Repository (HVSR) is a novel approach that combines the best of human SQL expertise with AI's pattern-matching capabilities. At its core, HVSR is a knowledge management system that:
Captures Expert Knowledge
Creates a growing repository of optimized, verified SQL queries that represent the gold standard of SQL craftsmanship
Leverages AI for Matching
Uses large language models to match new natural language questions with existing verified queries
Adapts Verified Queries
Makes targeted modifications to existing queries rather than generating new ones from scratch
Provides Fallback Options
Gracefully degrades to traditional text-to-SQL when no match is found
HVSR directly addresses the key challenges in text-to-SQL applications:
- Performance issues: Human verification ensures queries are optimized for your specific database
- Inconsistent quality: Users get the same high-quality queries for similar questions
- Knowledge sharing: SQL expertise is captured and made available throughout the organization
- Continuous improvement: The repository grows more valuable over time as more queries are verified
Building HVSR: A Two-Phase Implementation
The HVSR approach consists of two distinct phases:
Phase 1: Expert Validation and Storage
A specialized interface for data analysts to validate and optimize AI-generated queries:
- • Review AI-generated queries
- • Apply optimizations based on expertise
- • Add context and explanation
- • Store validated queries in a central repository
Phase 2: Intelligent Query Matching and Execution
A user-facing application that matches questions with verified queries:
- • Load the HVSR repository
- • Match the question using semantic similarity
- • Retrieve the gold-standard query
- • Adapt if needed for specific variations
- • Execute the query via database API
- • Fall back to traditional text-to-SQL if no match
A Practical Example: HVSR in Action
Let's walk through a real-world example of how HVSR transforms text-to-SQL quality through human validation: Check the demo below
Phase 1: Expert Validation | Phase 2: Intelligent Matching
Step 1: Data Analyst Uses the Validator App
As a data analyst with E-Commerce domain expertise, you log into the HVSR validation app and ask:
"How many orders were delivered in the year 2018?"
Step 2: Initial AI-Generated Query
The AI produces the following query:
SELECT COUNT(*) AS "Number of Orders Delivered in 2018"
FROM "ECommerce"."geographical_orders_analysis"
WHERE "order_status" = 'delivered'
AND TO_TIMESTAMPTZ('yyyy-MM-dd', SUBSTR("delivery_date", 0, 10)) BETWEEN
TO_TIMESTAMPTZ('yyyy-MM-dd', '2018-01-01') AND
TO_TIMESTAMPTZ('yyyy-MM-dd', '2018-12-31');While this query is syntactically correct, it demonstrates several issues that only a domain expert would identify:
- It uses overly complex date conversions (TO_TIMESTAMPTZ with substring operations)
- It focuses on the delivery_date field rather than the more appropriate purchase_time field
- It may not perform optimally due to the date conversion functions
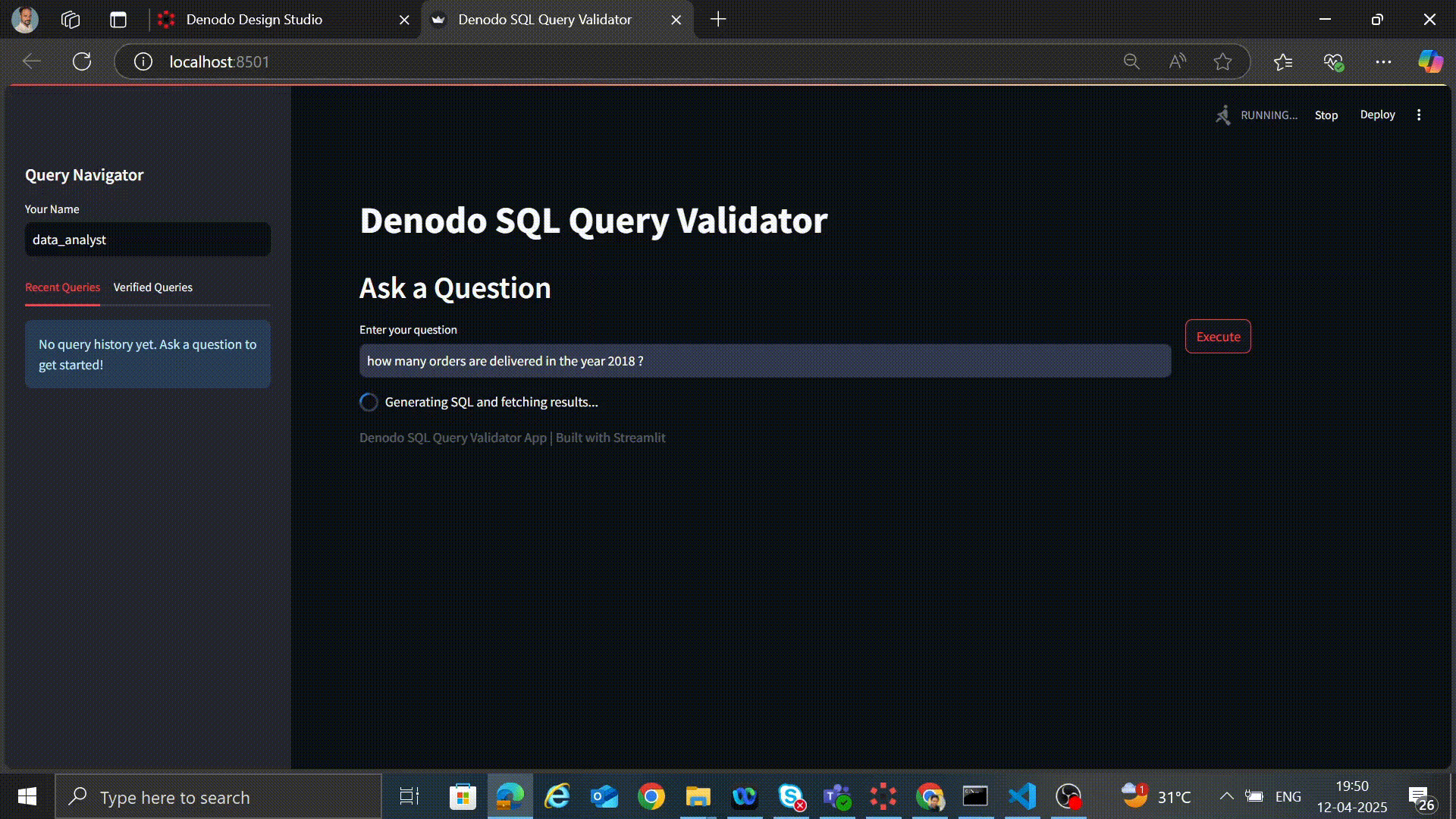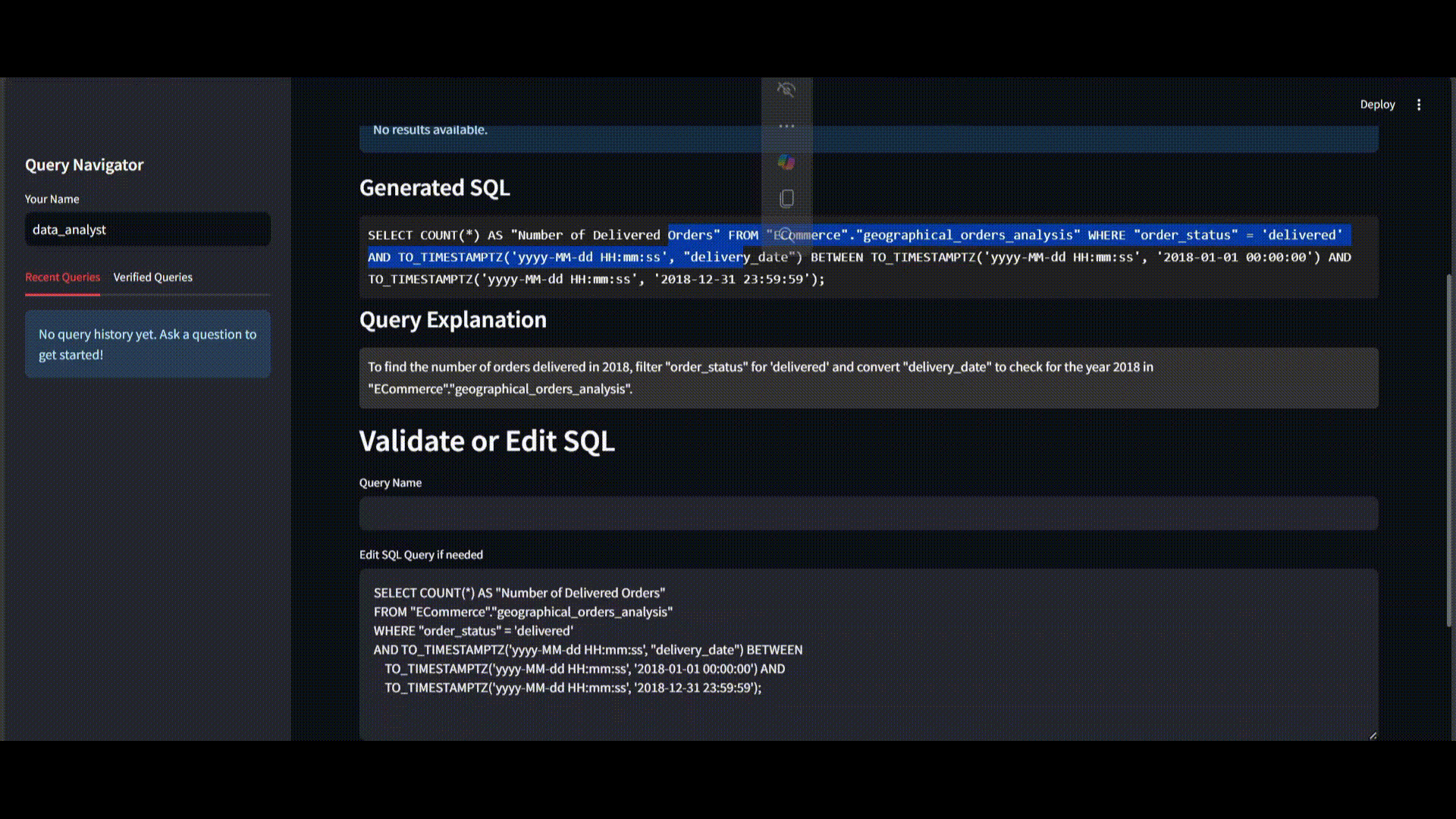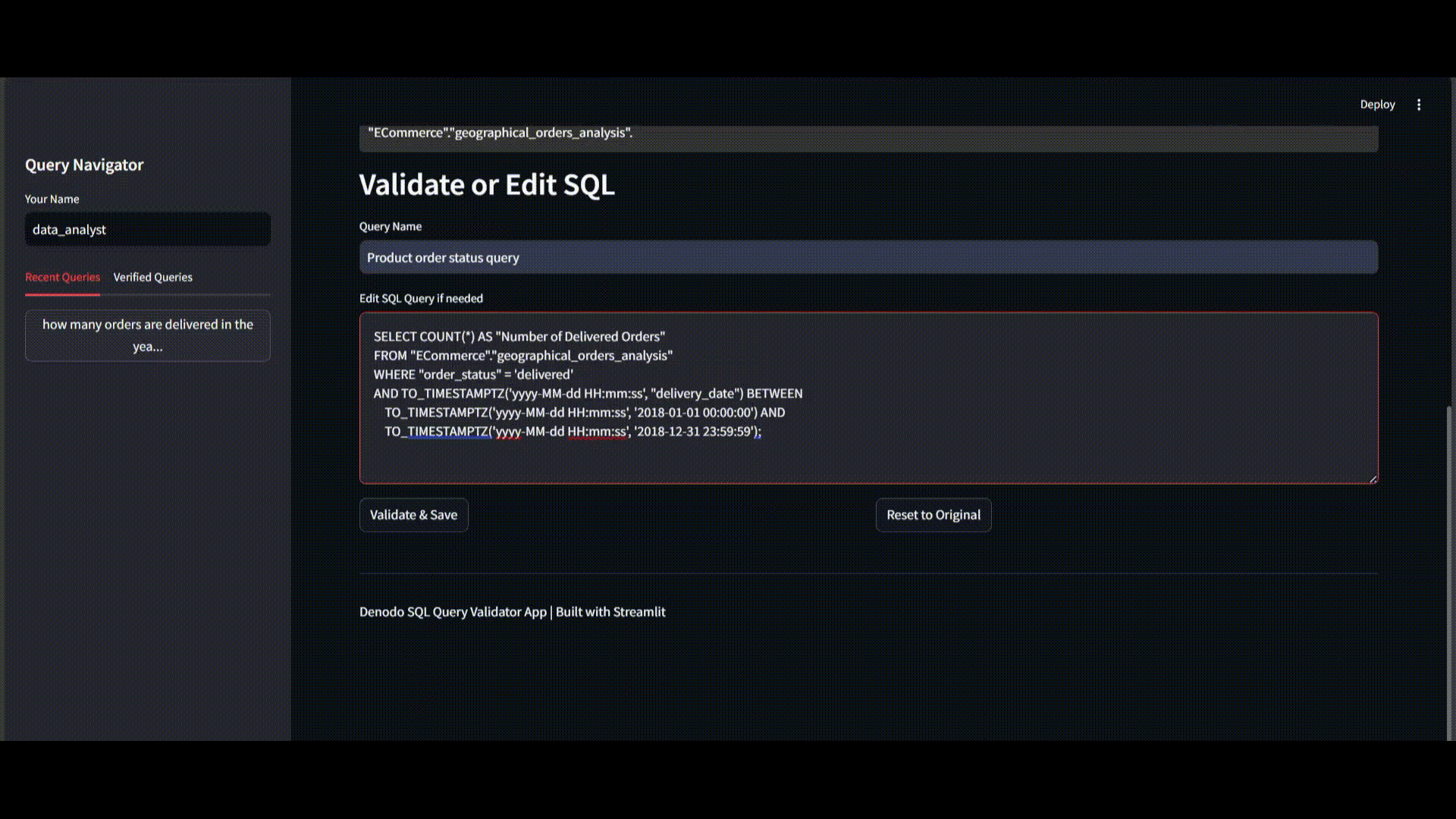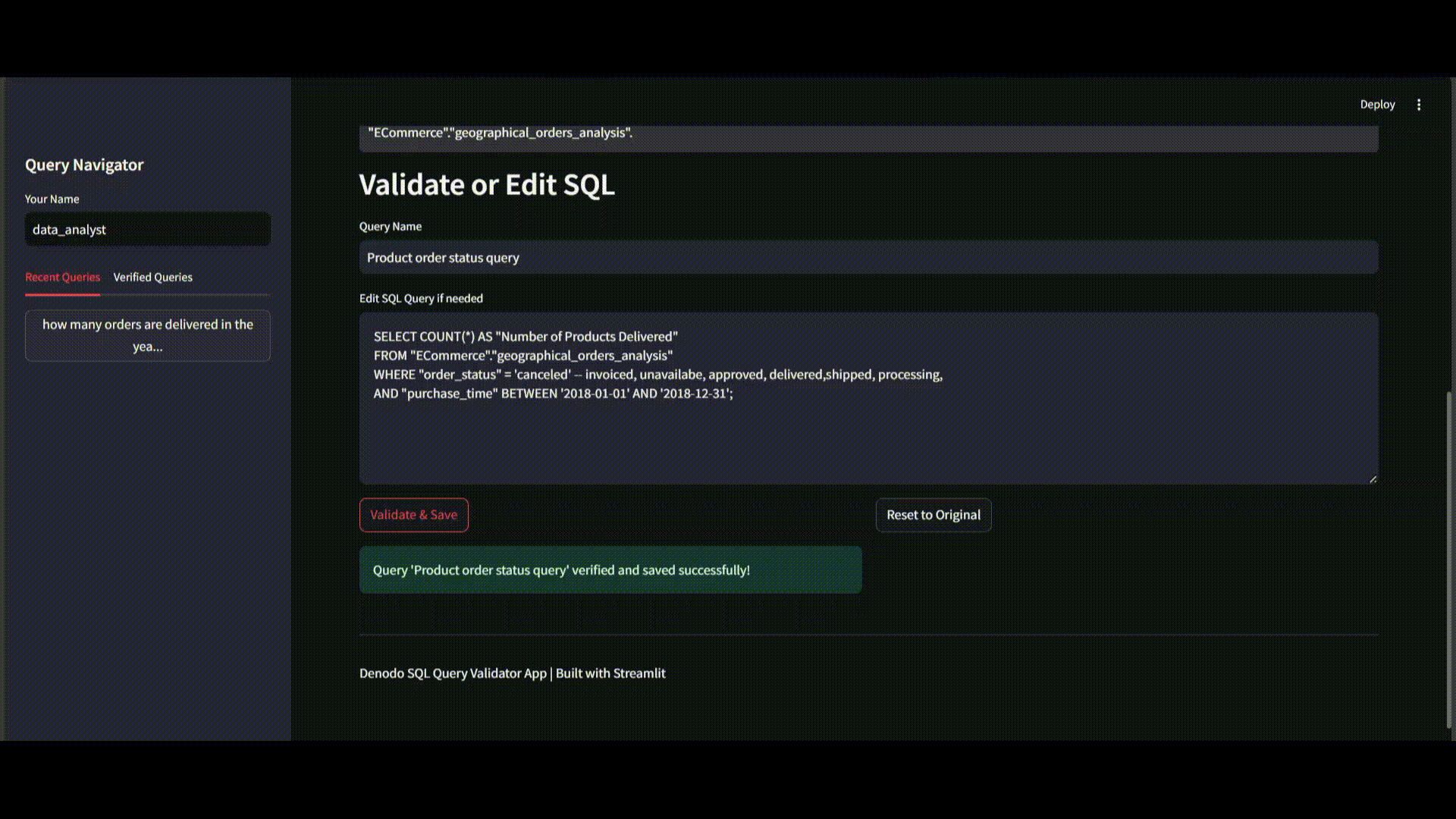
Step 3: Expert Validation and Optimization
As the data analyst, you review this query and apply your domain knowledge to create a more effective version:
SELECT COUNT(*) AS "Number of Products Delivered"
FROM "ECommerce"."geographical_orders_analysis"
WHERE "order_status" = 'delivered' -- invoiced, unavailable, approved, delivered, shipped, processing
AND "purchase_time" BETWEEN '2018-01-01' AND '2018-12-31';Your optimized query offers several critical improvements:
- Simplified date handling: Direct comparison instead of complex conversions improves performance
- Better field selection: Using purchase_time rather than delivery_date aligns with business logic
- Added domain context: Comments listing all possible status values provide context for future adaptations
- Cleaner syntax: Removed unnecessary functions that could impact query performance
Step 4: Saving to the HVSR Repository
You save this validated query to the YAML repository with additional metadata:
verified_queries:
- name: product orders status query
question: how many orders were delivered in the year 2018?
verified_at: 15th April 2025
verified_by: senior_data_analyst
query_explanation: Count orders with 'delivered' status within specified year using purchase_time field for better performance. Added comments on available status values for potential adaptation.
sql: |
SELECT COUNT(*) AS "Number of Products Delivered"
FROM "ECommerce"."geographical_orders_analysis"
WHERE "order_status" = 'delivered' -- invoiced, unavailable, approved, delivered, shipped, processing
AND "purchase_time" BETWEEN '2018-01-01' AND '2018-12-31';Step 5: Future Query Matching
When another user asks a similar question like "How many orders were shipped in 2019?", the system:
- • Semantically matches the question to your verified query
- • Identifies needed modifications (status: delivered → shipped, year: 2018 → 2019)
- • Adapts your optimized query with these specific changes
- • Returns results using your expert-crafted SQL pattern
✨ The Advantages of Expert Validation
- Domain knowledge integration: Your understanding becomes embedded in the system
- Performance optimization: Your simplified date handling improves query speed
- Contextual enrichment: Your comments make future adaptations more accurate
- Knowledge sharing: Your expertise is now available to all users
- Continuous improvement: As more validated queries join the repository, the system becomes increasingly capable
Implementation Strategy: Starting Small, Scaling Smart
Implementing HVSR doesn't require a massive overhaul of your data infrastructure. Start with these steps:
Identify High-Value Queries
Focus first on frequently asked questions or business-critical analyses
Build Your Validation Process
Set up the HVSR validation app for your SQL experts
Create Initial Repository Entries
Seed your repository with 20-30 high-quality verified queries
Implement Matching
Start routing user questions through the semantic matching system
Measure and Iterate
Track match rates, performance improvements, and user satisfaction
As your repository grows, the system becomes increasingly powerful, creating a virtuous cycle of improvement.
Conclusion: The Future of Human-AI Collaboration in Data
HVSR represents a fundamental shift in how we think about AI for data access. Rather than treating AI as a replacement for human expertise, it creates a framework where human knowledge amplifies AI capabilities, and AI extends the reach of human expertise.
This pattern—where human validation creates "golden examples" that AI can learn from and adapt—will likely extend far beyond SQL generation into other domains where specialized knowledge meets general-purpose AI.
By implementing HVSR today, you're not just solving immediate text-to-SQL challenges—you're establishing a blueprint for the next generation of human-AI collaboration in your organization. You're creating a system where the whole is greater than the sum of its parts, where human expertise and AI capabilities combine to create something neither could achieve alone.
In a world where data-driven decisions are increasingly crucial to competitive advantage, that combination might be your most valuable asset yet.
Resources
Need Help Implementing HVSR?
I can help you design and build a Human-Verified SQL Repository tailored to your organization's needs.