Learn to create adaptive database query systems that fix their own mistakes and optimize performance automatically using Stanford's Agentic Context Engineering
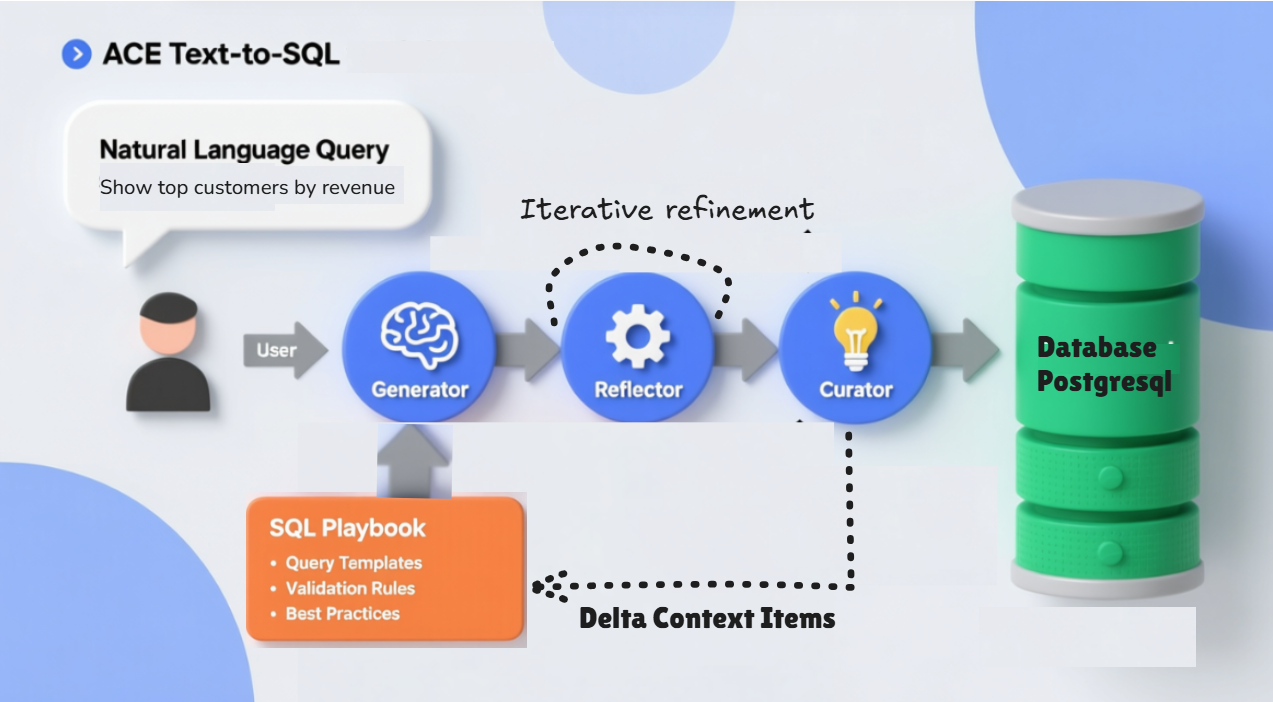
Image Generated by Author Using AI
Most text-to-SQL systems today use multi-agent architectures with monolithic prompts. They generate working queries through complex chains of specialized agents — one for schema analysis, another for query planning, a third for SQL generation.
These monolithic systems work. They'll turn "show me top customers" into executable SQL. But the results are inefficient and frustrating.
They use SUBSTRING() when LEFT() runs faster. They write nested subqueries instead of clean JOINs. They crash with PostgreSQL GROUP BY errors that any junior developer spots instantly.
The fix is to tweak the prompts for hours. Hope the changes don't break something else and repeat the loop.
I built a better approach using Stanford's Agentic Context Engineering (ACE) framework. The system fixes its own mistakes and gets smarter with every query.
Why Current Solutions Fail
Most teams face an expensive choice. Fine-tune your model or craft better prompts.
Fine-tuning costs thousands of dollars and weeks of compute time. You need labeled data, GPU clusters, and model redeployment. One database schema change breaks everything.
Prompt engineering seems cheaper but hits two walls:
- Brevity bias makes systems optimize for short prompts that lose important details.
- Context collapse happens when systems rewrite their knowledge into generic, useless summaries.
Traditional multi-agent systems compound these problems by using monolithic prompts for each agent. When errors occur, you're debugging massive blocks of text across multiple components.
ACE takes a different approach. It represents context as structured, itemized bullets rather than single monolithic prompts. Each bullet contains one focused piece of knowledge — a schema rule, SQL pattern, or common mistake. This design enables surgical updates instead of wholesale rewrites.
The system learns domain expertise in plain English that you can read and modify. Need GDPR compliance? Remove specific rules. Want new business logic? The system learns it from examples.
How ACE Works
ACE uses three components that work like a software development team:
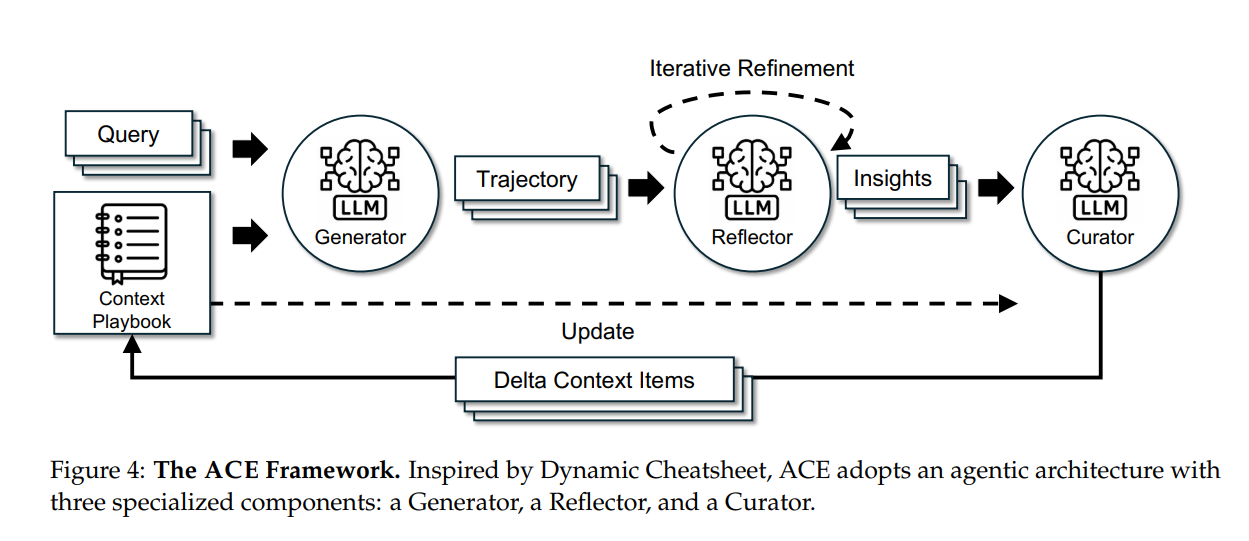
Image from Stanford Research Paper
- The Generator writes SQL queries using current knowledge and database schema information. Think of it as your SQL developer.
- The Reflector analyzes what went wrong when queries fail or perform poorly. It's your code reviewer that learns patterns across hundreds of failures.
- The Curator takes those insights and updates the knowledge base using small, targeted changes. It adds new rules, updates counters, and removes outdated advice. The key innovation is incremental delta operations on structured bullet items instead of massive rewrites that lose hard-won knowledge.
Each bullet contains exactly one piece of knowledge:
sr-00003: customer.customer_id → rental.customer_id (1:N relationship)code-00001: Revenue template using explicit JOINsts-00002: PostgreSQL requires ALL non-aggregated columns in GROUP BY
This granular structure enables surgical updates. When the system learns a new pattern, the Curator adds one bullet. When a rule proves harmful, it deletes just that item. The playbook grows organically without losing existing knowledge.
Memory Architecture
The system stores knowledge in three places:
- Episodic Memory logs every query attempt, creating a searchable history of successes and failures
- Semantic Memory holds database schema, join patterns, and SQL examples in a vector database
- Procedural Memory maintains the evolving SQL playbook as structured bullet items
The playbook structure prevents context collapse. Instead of one massive prompt that gets rewritten into generic text, ACE maintains hundreds of focused bullets. Each item tracks its own usage statistics and effectiveness scores:
{
"id": "sr-00001",
"content": "customer.customer_id → rental.customer_id (1:N relationship)",
"usage_count": 45,
"helpful": 42,
"harmful": 3
}This granular tracking enables the system to promote helpful patterns and prune harmful ones without losing everything else.
Real Performance Gains
The results prove ACE works. Stanford's evaluation showed 86.9% lower adaptation time compared to traditional prompt optimization. While methods like GEPA needed over 53,000 seconds and 1,434 attempts to improve, ACE finished the same work in 951 seconds with 238 attempts.
ACE matched IBM's top-ranked production agent (powered by GPT-4) using a smaller open-source model. Performance improved 10.6% offline and 8.6% online without changing a single model parameter.
Building a Production-Ready System
I built this using the PostgreSQL DVD rental database — a DVD rental store with 15 tables, including customer, rental, payment, film, and inventory. This creates realistic complexity with multiple join paths and business logic.
Architecture Components
The architecture uses five core components working together:
- Memory Fabric stores knowledge in three layers. Episodic Memory logs every query attempt in PostgreSQL for replay and debugging. Semantic Memory holds schema information, join patterns, and SQL examples in the ChromaDB vector database for fast retrieval. Procedural Memory maintains the evolving playbook as structured JSON.
- Generator produces SQL using current playbook knowledge plus retrieved schema information via Retrieval-Augmented Generation (RAG). It receives the user query, relevant playbook bullets, and schema metadata to generate executable PostgreSQL.
- Reflector analyzes outcomes when queries fail or perform poorly. It compares generated SQL against ground truth, identifies error categories like aggregation or join mistakes, and extracts reusable insights.
- Curator takes reflector insights and surgically updates the playbook using incremental delta operations. Instead of rewriting everything, it adds new rules, updates counters, or removes harmful advice.
- Evaluator scores SQL quality using rubrics for validity, correctness, efficiency, and safety. Queries scoring above 85% get automatically promoted to update the playbook.
Tech Stack
- • LangChain for LLM orchestration
- • ChromaDB for vector storage
- • OpenAI GPT-4 for reasoning
- • PostgreSQL for database and episodic memory
- • Python for backend implementation
The System in Action
When someone asks "Show me top customers by revenue," the system:
- Retrieves relevant schema knowledge using vector similarity search
- Loads playbook bullets that match the query pattern
- Assembles context within token budgets
- Generates SQL with step-by-step reasoning
- Executes it against the DVD rental database
- Analyzes success or failure for insights
- Updates playbook with delta operations only if required
The playbook starts simple with rules like customer.customer_id → rental.customer_id (1:N relationship) and grows into sophisticated patterns like "When calculating customer revenue, always use explicit GROUP BY with all non-aggregated columns to avoid PostgreSQL errors."
Demo: Performance Optimization Learning
Here's where the system gets really interesting. A user asks: "Show me the rentals for each month in the year 2005?"
Real-time learning demonstration
Initial Query (Inefficient)
The system generates working SQL but uses inefficient patterns:
SELECT
EXTRACT(MONTH FROM r.rental_date) AS month,
COUNT(r.rental_id) AS rental_count
FROM rental r
WHERE EXTRACT(YEAR FROM r.rental_date) = 2005
GROUP BY month
ORDER BY month;
This works but performs poorly. The EXTRACT() functions in WHERE and GROUP BY prevent index usage and create unnecessary computation.
Learning from Feedback
I provide feedback: "When aggregating by month or year on timestamp columns, use date_trunc for grouping and range filters in WHERE so indexes can be used. Never wrap date columns in EXTRACT/DATE_PART/CAST inside WHERE."
The system responds: "Playbook updated based on your instruction." The last update time changes from 12:12 to 12:14, indicating the update in the SQL playbook.
Optimized Query (After Learning)
When I ask the same question again, it generates optimized SQL:
SELECT
date_trunc('month', r.rental_date) AS rental_month,
COUNT(*) AS rental_count
FROM rental r
WHERE r.rental_date >= '2005-01-01' AND r.rental_date < '2006-01-01'
GROUP BY rental_month
ORDER BY rental_month;
The Curator added a new bullet to the playbook: ts-00008: Use date_trunc for time grouping and range filters for WHERE clauses to enable index usage.
This learning applies to all future date-based queries. The system builds performance optimization knowledge through real usage.
Continuous Improvement
The real breakthrough is the nightly learning cycle. The system replays recent failures with different playbook versions using Thompson sampling to find what actually works better. Successful changes get promoted to production automatically.
This creates a text-to-SQL system that improves with use. Not through expensive retraining, but through accumulated real-time curated instructions. More queries make it smarter.
What This Means for Text-to-SQL Systems
This approach transforms how organizations handle database queries. Traditional text-to-SQL systems require constant maintenance — tweaking prompts, updating examples, retraining models when schemas change.
ACE-based systems become more valuable over time through accumulated wisdom. Every failed query teaches the system something new. Every performance optimization gets encoded as reusable knowledge.
Cost Benefits
The cost benefits are substantial. My implementation reduces adaptation time by 86.9% compared to traditional prompt optimization methods. Where other systems need hundreds of expensive LLM calls to improve, ACE achieves better results with surgical updates to specific knowledge items.
Organizational Learning at Scale
More importantly, the system enables organizational learning at scale. Database administrators can focus on schema design instead of prompt engineering. Domain experts can contribute business rules through natural feedback rather than technical prompts. The knowledge base becomes a living asset that captures institutional wisdom.
Consider regulatory compliance scenarios. When GDPR requires removing customer data references, you delete specific playbook bullets rather than retraining entire models. When new business rules emerge, the system learns them organically from query patterns and feedback.
The Fundamental Shift
The implications extend beyond SQL generation. We're moving toward AI systems that truly adapt to their environments rather than requiring expensive retraining cycles. These systems become colleagues that understand your domain's nuances, your team's preferences, and your organization's constraints.
The fundamental shift is from static AI that degrades over time to adaptive AI that improves with use. Your text-to-SQL system doesn't just translate language to queries — it builds institutional knowledge that compounds with every interaction.
Try It Yourself
Want to see ACE in action? The complete implementation is available on GitHub with setup instructions for the PostgreSQL dvdrental database.
In the next part, I will cover how knowledge bases like Episodic, Semantic, and Procedural will benefit the Text2SQL systems with the ACE framework
Resources
- Stanford Research Paper: Agentic Context Engineering
- GitHub Repository: Self-Improving Text2SQL Implementation
Need Help Implementing This?
I offer consulting services for Text-to-SQL systems. Let's discuss your requirements.
Schedule a Consultation